Decoding Proteins with Transformers
Transformer models, renowned for their ability to capture long-range dependencies in sequential data, have revolutionized protein language modeling. Pretrained models like ESM and ProtBERT, trained on massive datasets of protein sequences, leverage the Transformer architecture to learn intricate representations of protein structures and functions. These models excel at tasks such as protein function prediction, homology detection, and contact prediction, providing valuable insights into the complex world of proteins.
Persona-Knowledge interactive multi-context retrieval for grounded dialouge
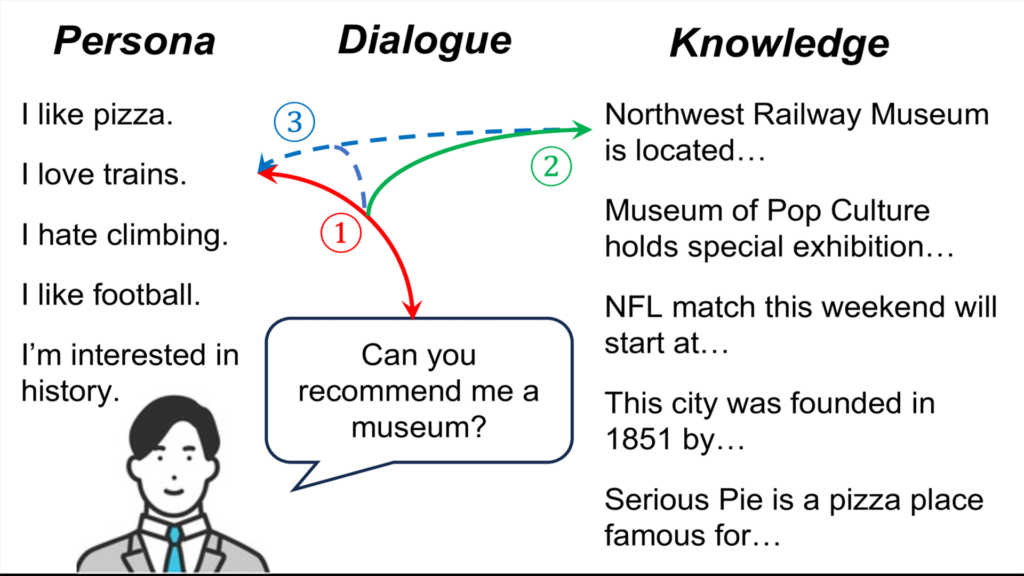
“Persona-Knowledge Interactive Multi-Context Retrieval for Grounded Dialogue” (PK-ICR) is a novel approach to improving conversational AI systems. PK-ICR focuses on enhancing the retrieval of relevant information, such as a user’s personality (persona) and external knowledge, to generate more engaging and informative dialogue responses. By considering both persona and knowledge simultaneously, PK-ICR aims to create a more comprehensive understanding of the user and the conversation context. This allows the system to generate responses that are not only factually accurate but also personalized and relevant to the user’s individual preferences and interests.
Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Foundation models, primarily based on Transformers, struggle with computational inefficiency on long sequences. To address this, Mamba is introduced, a new model architecture that replaces attention with selective state space models (SSMs). Mamba enables content-based reasoning, achieves linear scaling with sequence length, and surpasses Transformers in performance across various modalities, including language, audio, and genomics.